一、准备工作
先确认网页访问、网络与浏览器设置,再开始操作使用网页挂载版前,建议先确认当前浏览器可以正常访问 miR Designer 页面,并允许弹出新标签页。否则 Thermo、NCBI Record 和 BLAST 跳转都可能打不开。
1. 打开网页挂载版
直接访问 https://mir-designer.haverlun.com 即可开始使用,无需本地启动服务。
2. 确认网络
本软件依赖外部站点检索和跳转。若网络受限,最常见的影响是:变体加载慢、Broad 没返回、Thermo 或 BLAST 页面打不开。
3. 建议的演示路径
第一次培训时,最稳妥的顺序是:TP53 示例 → 选 transcript → Broad → Thermo 对照 → BLAST。
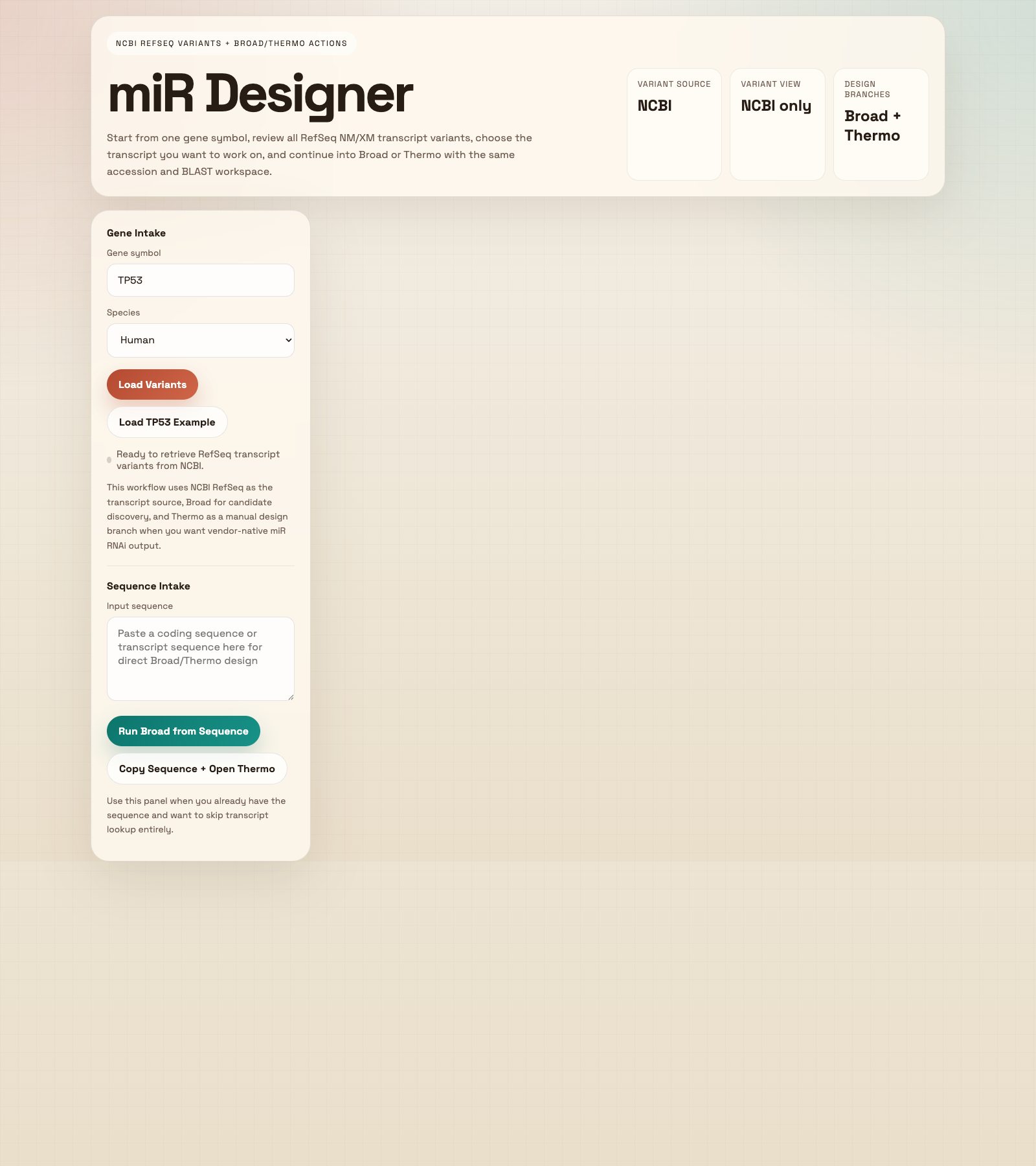
二、图 1:首页输入区
这一屏负责把用户引入 Gene 模式或 Direct Sequence 模式让用户先在左侧输入基因符号和物种,然后点击 Load Variants 载入 RefSeq transcript 集合。
如果只是教学,建议直接点击 Load TP53 Example,这样能稳定进入后续页面。
如果用户手里已经有 CDS 或 transcript 序列,可以跳过基因检索,直接在 Sequence Intake 区域操作。
图 1A:初始首页
原始截图,标注的是第一页最重要的 8 个入口位置。
 1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
说明:上方的 A / B / C 是流程步骤;截图里的 1-8 和下方图注对应的是界面位置编号。
输入标准基因符号,例如 TP53、EGFR。建议使用官方基因名,不要混用别名。
选择 Human、Mouse 或 Rat。后续 NCBI transcript 检索和 BLAST 过滤都会跟着这个物种走。
点击后向 NCBI 拉取该基因的 RefSeq transcript variants,并在右侧生成 Summary 与 Variant View。
一键加载 TP53/human 示例。培训、测试、录屏都建议从这个按钮开始。
这里会持续提示“正在加载”“加载成功”“请求失败”等状态。出现问题时先看这里,再排查网络或接口。
用于粘贴已有 nucleotide sequence。适合用户已经拿到 CDS 或 transcript,不想先走 gene lookup 时使用。
直接把输入序列送到 Broad 设计链路,右侧会立即出现候选 target 列表。
复制输入序列并打开 Thermo 页面。这是 Direct Sequence 模式下通往 Thermo 的手动分支入口。
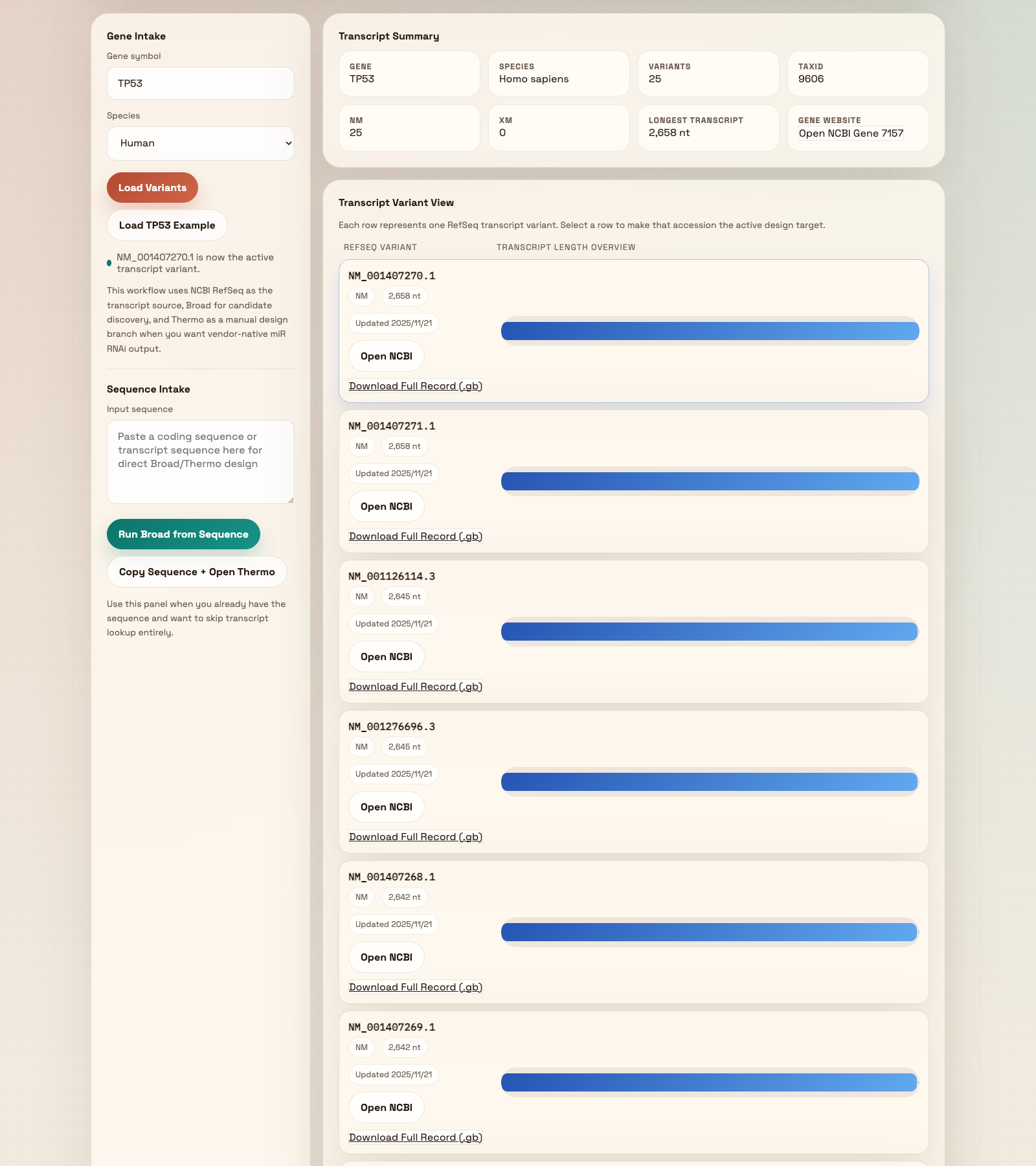
三、图 2:加载 transcript variants 并查看列表
这一屏告诉用户当前 gene 一共有多少个 RefSeq transcript 可用于后续设计系统会查询 NCBI 并在右侧展开 Transcript Summary 和 Transcript Variant View。
Summary 用来判断变体总数、NM/XM 组成和最长转录本;Variant View 用来挑选具体 accession。
每一行都带有 Open NCBI 和 Download Full Record (.gb) 两个原始数据入口。
图 2A:Transcript Summary + Variant View
这张图主要用于讲“如何理解 transcript 列表”。
 1
2
3
4
5
1
2
3
4
5
显示当前基因的物种、变体总数、NM/XM 数量、最长 transcript,以及 NCBI Gene 外链。
这里列出所有 RefSeq transcript variants。每一行都是一个可以点击的 accession 行。
点击任意一行,就会把该 transcript 设为当前 active target,并在下方解锁操作按钮。
打开该 accession 的 NCBI 页面。适合用户确认标题、版本、注释状态等原始信息。
直接下载该 transcript 的 GenBank 记录,方便做留档、复核或发给其他同事。
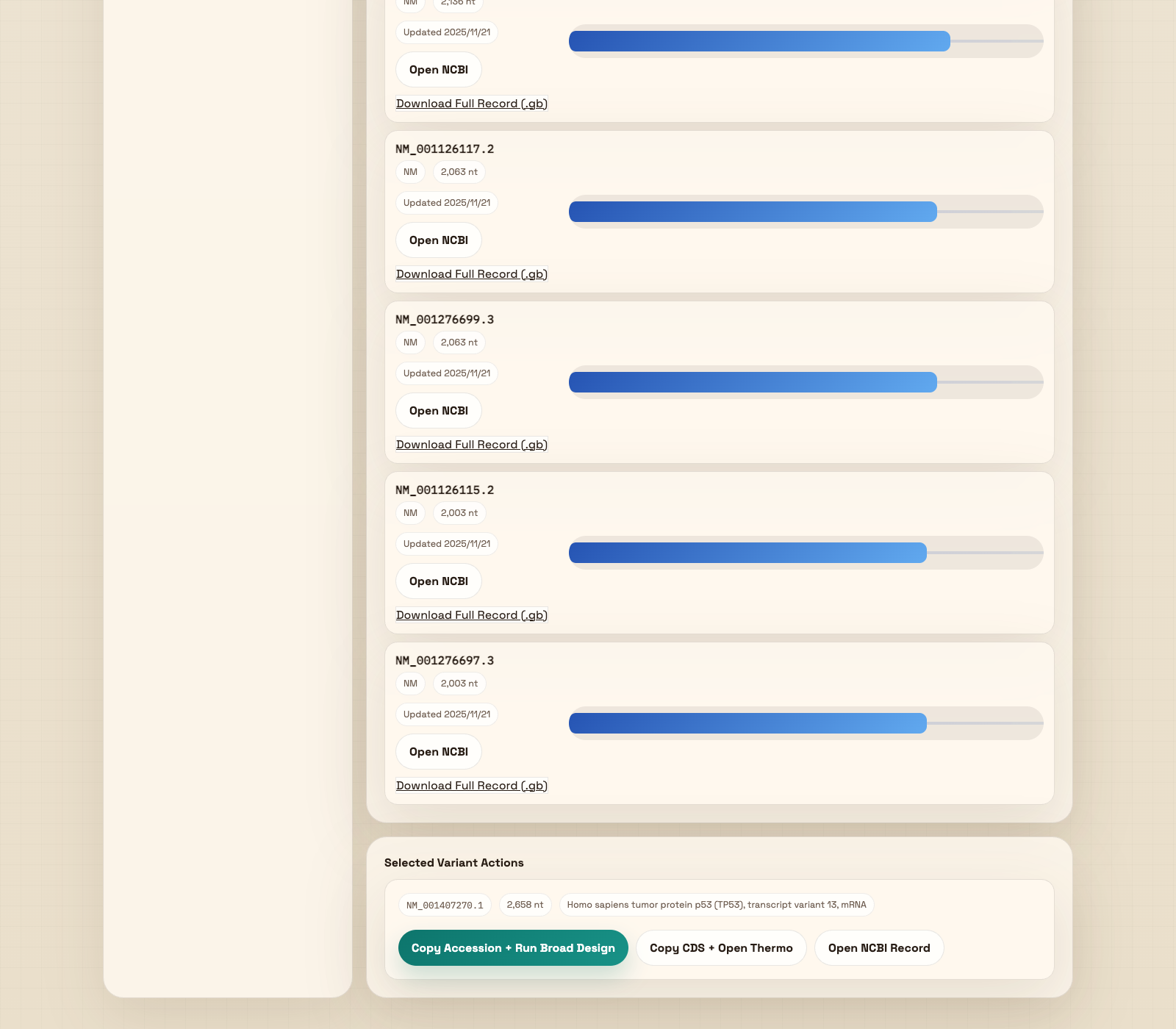
四、图 3:选中 transcript 后的操作按钮
这是标准工作流的分叉点:Broad、Thermo、NCBI Record重要:必须先点击一行 transcript,下面这一组按钮才会显示。虽然列表载入后会自动有默认 active accession, 但在 UI 上真正显示操作区,还是以“用户点击某一行”为触发。
图 3A:Selected Variant Actions
这是用户从 transcript 列表进入真正设计流程的关键一步。
 1
2
3
4
1
2
3
4
这里会显示当前被选中的 accession、长度和标题。用户可以在这里确认自己没选错 transcript。
推荐的主流程入口。点击后软件会用当前 accession 的 CDS 去跑 Broad,并在下一屏展示候选 targets。
适合走 Thermo 人工设计分支。软件会复制 CDS、打开 Thermo 新标签页,并把序列保留到当前页面工作区。
如果用户要再次确认 transcript 的完整记录,可直接从这里打开 NCBI 页面,不必回到列表行里找。
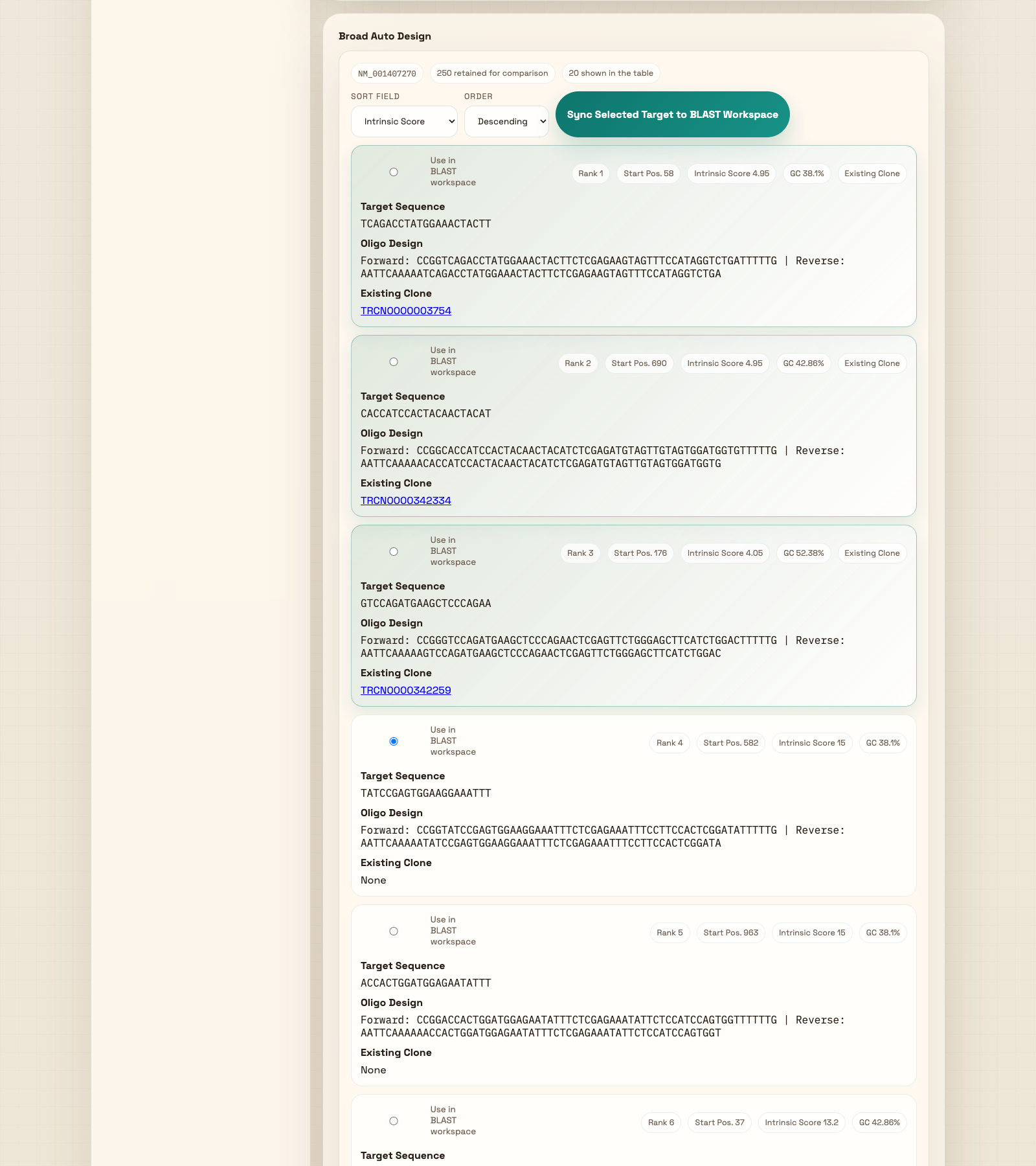
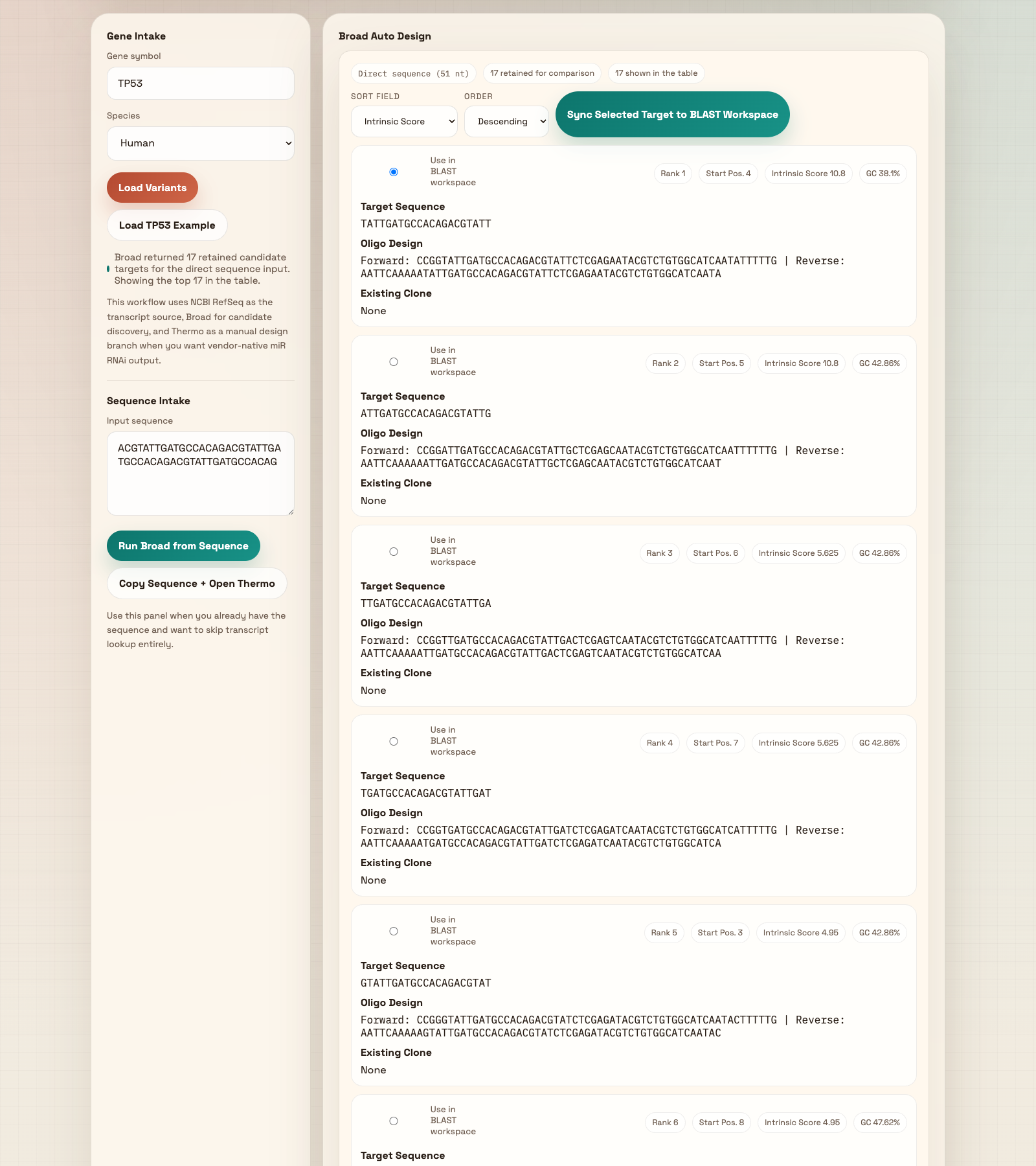
五、图 4:Broad Auto Design 结果页
这一屏负责筛选 Broad 候选、排序、挑选 target 并同步到 BLAST 工作区系统会把当前 transcript 的 CDS 发送给 Broad,返回候选 target 列表。
通常先按 Intrinsic Score 从高到低看,再结合 GC、Start Pos.、Existing Clone 做判断。
系统默认会把当前选中的 Broad target 自动放入后面的 BLAST Input Workspace,便于继续验证。
图 4A:Broad 设计结果与候选列表
图中显示的是当前 transcript 的 retained candidate targets。
 1
2
3
4
5
6
1
2
3
4
5
6
最上方会显示当前来源 accession、retained candidate 数量,以及当前展示条数。
切换按分数、起始位点、目标序列或 Existing Clone 来排序。培训时建议先保持默认的 Intrinsic Score。
控制升序 / 降序。默认用 Descending 最符合“先看高分候选”的习惯。
给某个 Broad candidate 打勾后,它会成为当前 target,并自动同步到下面的 BLAST 区域。
如果用户切换了 target,点这个按钮可以再次把当前 target 强制同步到 BLAST 工作区。
这里是最核心的结果:候选 target sequence、Oligo Design,以及是否已有 Existing Clone。
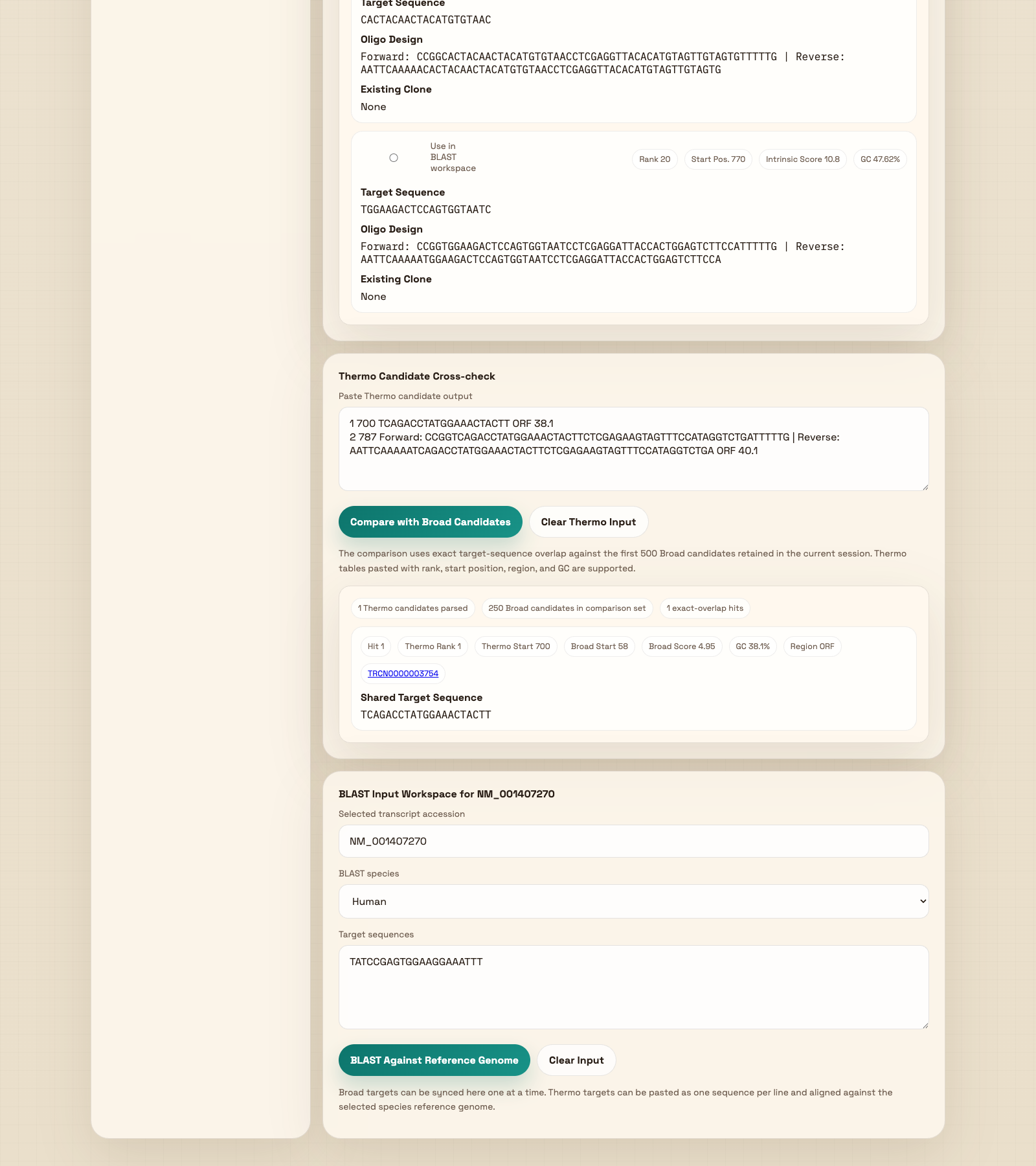
六、图 5:Thermo Candidate Cross-check 与 BLAST Workspace
这一步把 Thermo 的人工设计结果拉回本软件做交叉核对和 BLAST 验证本软件打开 Thermo 之后,用户在 Thermo 页面里继续操作;返回本软件时,把候选表格行粘贴到 Thermo 输入框。
系统会用 exact target-sequence overlap 去比对当前 Broad 候选集和 Thermo 粘贴结果。
如果 Broad target 已同步过来,直接点击 BLAST;如果是 Thermo 序列,则一行一个粘贴到 BLAST 输入框再点击 BLAST。
图 5A:Thermo 对照 + BLAST 工作区
这一屏适合讲“如何把外部 Thermo 结果拉回本系统验证”。
 1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
8
把 Thermo 候选输出粘贴到这里。支持形如 rank start sequence region gc 的行格式。
执行 Broad / Thermo exact overlap 比较。结果会显示匹配数量、Broad Score、Start Pos. 等信息。
清空当前 Thermo 粘贴内容,方便重新贴入另一批候选。
这里会告诉用户:共解析了几条 Thermo candidates、当前 Broad 集合有多少条、两边 exact-overlap 命中了几条。
这是当前 BLAST 工作区绑定的 transcript。培训时应提醒用户:先确认 accession 没错,再继续 BLAST。
设置 BLAST 的物种过滤条件。通常应与最初 Gene Intake 中的物种保持一致。
这里接收 Broad 自动同步过来的 target,或由用户手工粘贴的一行一条 Thermo 序列。
点击后会打开新的 NCBI BLAST 标签页,并把当前 target sequences 预装进去。
七、图 6:Direct Sequence 快捷流程
适合“用户已经有序列,只想直接设计”的场景这条路径完全跳过 transcript lookup。你不需要先输入 gene symbol,也不需要先选某个 accession;只要粘贴序列即可。
建议使用纯 nucleotide sequence。系统会自动清理空格、换行和非 A/C/G/T/U 字符。
右侧会直接生成 Broad candidates,并把当前选中的 target 放到 BLAST 工作区。
点击 Copy Sequence + Open Thermo,软件会复制当前序列并打开 Thermo 页面。
图 6A:Direct Sequence 模式
这张图同时展示了左侧输入序列和右侧 Broad 返回结果。
 1
2
3
4
1
2
3
4
把已有序列粘贴到这里。图中演示的是 51 nt 样例序列。
直接执行 Broad 设计,不再依赖 NCBI transcript 检索。
复制序列并打开 Thermo,适合直接序列来源的手工设计场景。
右侧会显示 retained candidate 数量和排序后的候选列表,操作逻辑与图 4 相同。
八、常见问题与讲解建议
给培训老师、交付同事和支持人员使用为什么点了 Load Variants 没反应?
- 先看首页状态区是否显示请求错误。
- 刷新当前网页后重试一次。
- 检查当前网络是否能访问 NCBI。
为什么看不到 Selected Variant Actions?
- 需要真正点击一行 transcript。
- 如果只加载了列表但没点行,下方操作区不会显示。
为什么 Thermo / BLAST 没打开?
- 多数情况是浏览器拦截了新标签页。
- 请允许当前页面弹窗,然后重试对应按钮。
Broad 结果太多时怎么教用户选?
- 先按默认的
Intrinsic Score看前几条。 - 再结合
GC、Start Pos.、Existing Clone做筛选。
Thermo 对照区支持什么格式?
- 一行一个候选。
- 推荐格式:
rank start sequence region gc。 - 例如:
1 714 ACTCCTTAGCTTGATTGAGTA ORF 38.1。
给最终用户的最佳引导话术
- 先用 TP53 示例跑一遍全流程,让用户建立整体心智模型。
- 第二次再换成用户自己的基因或序列。